안녕하세요, 하이스트레인저 백엔드 엔지니어 이상훈입니다.
개발자들 사이에서는 “돌아가는 코드는 건드리지 않는다”라는 격언이 있습니다. 하지만 그 코드가 비즈니스의 성장을 가로막고 있다면 어떨까요?
최근 저는 씨네랩(Cinelab) 서비스 리뉴얼 프로젝트를 진행하며, 수년간 쌓인 레거시 데이터를 새로운 시스템으로 이관하는 작업을 맡았습니다. 단순히 테이블을 옮기는 작업이었다면 mysqldump를 썼을 겁니다. 하지만 제가 마주한 현실은 EC2 로컬에 묶인 이미지 파일들, 암호 같은 상태 값들, 그리고 테스트와 운영 데이터가 뒤섞인 ‘카오스’ 그 자체였습니다.
오늘은 이 혼란스러운 데이터를 어떻게 단 한 건의 유실 없이 이관했는지, 그 치열했던 과정을 공유합니다.
DB 마이그레이션, 다 같은 작업이 아닙니다
본격적인 이야기로 들어가기에 앞서, 우리가 흔히 말하는 DB 마이그레이션에 대해 잠시 짚고 넘어갈까 합니다. 마이그레이션은 목적과 작업 방식에 따라 크게 세 가지로 나눌 수 있습니다.
동종 마이그레이션 (Homogeneous Migration)
같은 DB 엔진 내에서 버전만 올리거나(예: MySQL 5.7 → 8.0), 서버만 이동하는 경우입니다. 스키마 변경이 거의 없어 비교적 난이도가 낮습니다.이기종/플랫폼 마이그레이션 (Heterogeneous/Platform Migration)
DB 엔진을 바꾸거나(Oracle → MySQL), 온프레미스(On-premise) 환경에서 클라우드(Cloud) 환경으로 인프라를 옮기는 작업입니다. 인프라적인 고려사항이 많습니다.애플리케이션/스키마 리팩토링 (Schema Refactoring)
서비스 로직의 변화에 따라 DB 구조(Schema) 자체를 뜯어고치는 작업입니다. 데이터의 의미를 재해석하고 매핑해야 하므로 가장 난이도가 높고 위험 부담이 큽니다.
제가 이번에 진행한 작업은 2번과 3번이 혼합된 형태였습니다.
물리적으로는 EC2 내부에 설치된 로컬 MySQL을 AWS RDS로 옮겨야 했고(플랫폼 이관), 논리적으로는 레거시 스키마를 완전히 새로운 엔티티 구조로 재설계(스키마 리팩토링)하여 데이터를 이전하여야 했습니다.
마주한 레거시의 실태
리뉴얼을 위해 기존 DB를 분석하면서 마주한 상황은 생각보다 심각했습니다.
데이터의 혼란
일관성 없는 네이밍:
UserEntity와users테이블이 공존하고, 컬럼명은camelCase와snake_case가 무분별하게 섞여 있었습니다.정체를 알 수 없는 매직 넘버(Magic Number): 게시글 상태가 0, 1, … 9 등의 숫자로만 저장되어 있었습니다. 문서화된 내용이 전혀 없어, 레거시 코드의 비즈니스 로직을 한 줄 한 줄 역추적해야만 그 의미(0=대기, 1=승인, 9=삭제 등)를 파악할 수 있었습니다.
더러운 데이터(Dirty Data): 운영 DB 안에 개발 초기에 생성된
test,asd,admin123같은 무의미한 데이터가 실제 유저 데이터와 구분 없이 섞여 있었습니다. 심지어 OAuth ID 필드가 깨져있거나 비어있는 유령 회원들도 다수 존재했습니다.
코드에도 없는 ‘유령 필드’
가장 난감했던 건 도대체 어디에 쓰는지 알 수 없는 컬럼들이었습니다. DB 테이블에는 분명히 존재하고 데이터도 들어있는데, 정작 프로젝트 전체 코드를 아무리 검색해도 해당 컬럼을 사용하는 로직이 단 한 줄도 나오지 않는 필드들이 있었습니다.
“이거 지워도 되는 건가? 혹시 DB 프로시저나 외부 시스템에서 몰래 쓰고 있는 건 아닐까?”
이러한 불확실성은 이관 작업을 진행하는 내내 반복하여 데이터를 검증하게 만들었고, 결국 이 컬럼들이 과거 특정 시점에 쓰이다가 버려진 ‘유령 필드’임을 확신하기까지 꽤 많은 시간이 필요했습니다.
파일 시스템의 강결합
또 다른 어려움은 이미지 저장 방식이었습니다.
기존 서비스는 이미지를 EC2 서버의 로컬 디렉토리(upload/)에 저장하고, DB에는 상대 경로만 저장하고 있었습니다. 서버가 스케일 아웃(Scale-out)될 수 없는 구조였죠. 리뉴얼된 시스템은 AWS S3를 사용하기로 결정했으므로, 저는 DB 이관과 동시에 수천 장의 로컬 파일들을 S3로 업로드하고, DB에 저장된 상대 경로를 S3 URL로 교체(Replace)해야 하는 복합적인 과제를 안게 되었습니다.
이관 전략 수립
1. 왜 커스텀 스크립트 였나?
일반적으로 DB 마이그레이션에는 mysqldump나 AWS DMS, 혹은 CDC 같은 도구들이 널리 쓰입니다. 저 역시 처음엔 AWS DMS를 고려했으나, 이번 프로젝트는 단순 ‘이동’이 아니라, 비즈니스 맥락에 맞춘 논리적인 재가공이 필요한 작업이었기에 기성 도구로는 한계가 명확했습니다.
복잡한 비즈니스 로직: 탈퇴 회원 제외, HTML 포맷 변환 등 단순 매핑을 넘어서는 정제(Cleansing) 과정이 필수였습니다.
이관의 원자성(Atomicity): DB에는 성공적으로 들어갔는데 S3 업로드가 실패한다면? 이를 방지하기 위해 스크립트를 통해 이미지를 S3에 업로드하고 URL을 획득한 뒤 DB에 Insert하는 과정을 하나의 트랜잭션처럼 묶어서 처리해야 했습니다.
결국 데이터 오염을 씻어내고 파일 시스템과의 의존성을 안전하게 다루기 위해, 저는 자체 개발한 스크립트를 활용하여 마이그레이션하는 방식을 선택했습니다.
2. 이관 순서 정립
도구를 정한 뒤 마주한 두 번째 난관은 도대체 뭐부터 옮겨야 하는가였습니다.
처음엔 가장 복잡한 테이블부터 해결하려 했으나, 이는 곧 수많은 외래 키(Foreign Key) 오류로 이어졌습니다. 부모 데이터 없이 자식 데이터를 먼저 옮기려 했기 때문입니다.
그래서 저는 다음과 같이 데이터 위계(Hierarchy)를 세워 마이그레이션 순서를 재설계했습니다.
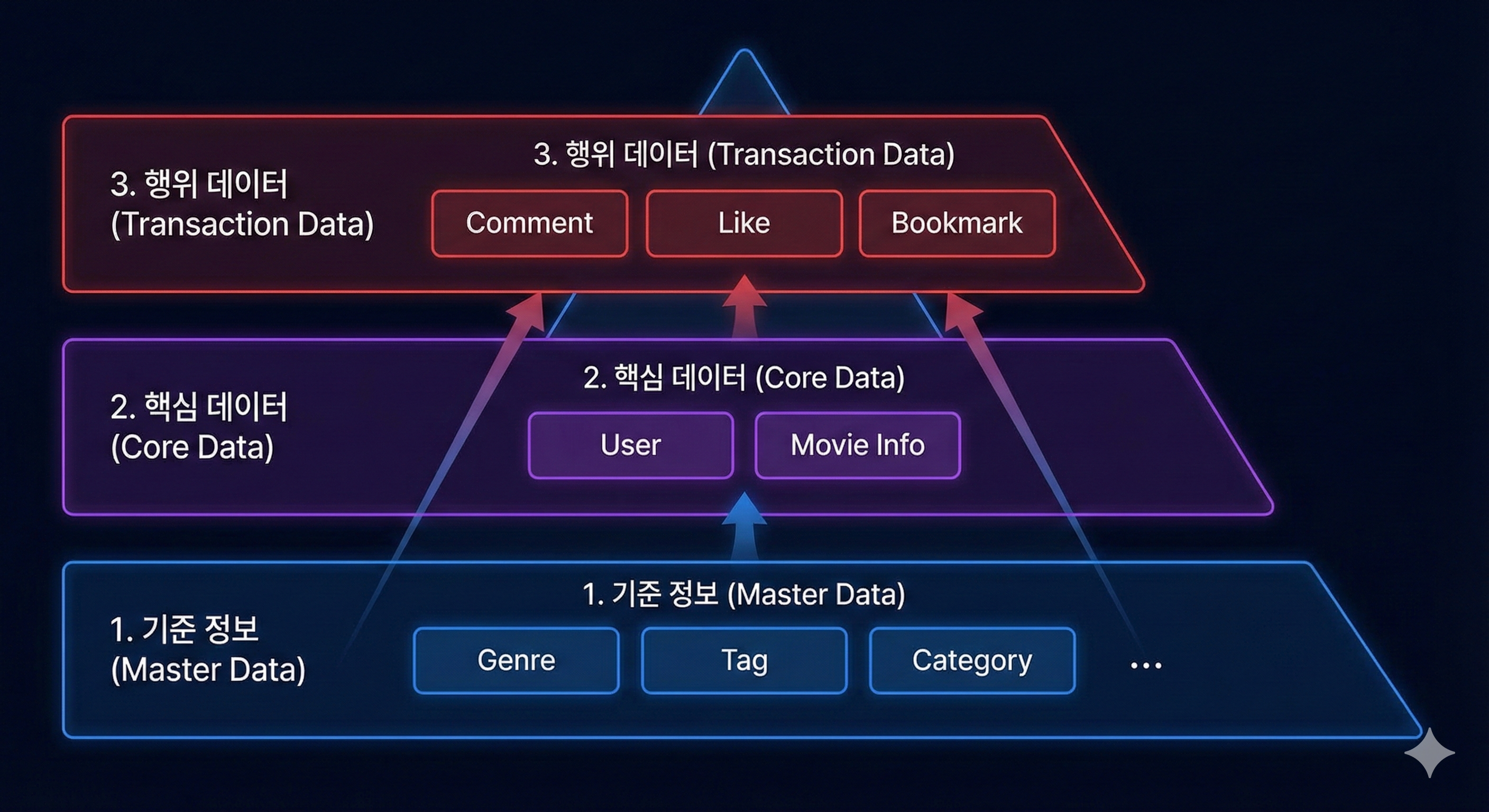
- 기준 정보 (Master Data): 장르, 태그, 카테고리 등 (참조의 기준)
- 핵심 데이터 (Core Data): 유저, 영화 정보 등 (서비스 주체)
- 행위 데이터 (Transaction Data): 댓글, 좋아요, 북마크 등 (활동 결과)
“Master → Core → Transaction” 순으로 진행하니, 데이터 꼬임이나 참조 무결성 에러를 원천적으로 차단할 수 있었습니다.
이관 프로세스 및 아키텍처
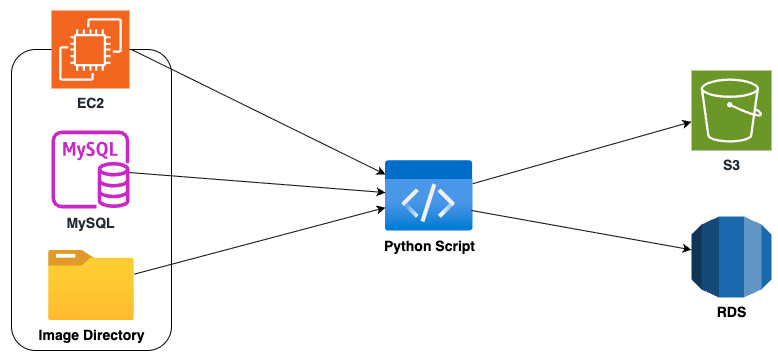
저는 Python을 이용해 ETL(Extract, Transform, Load) 파이프라인을 구축했습니다.
Step 1. 매핑 및 설계(Mapping)
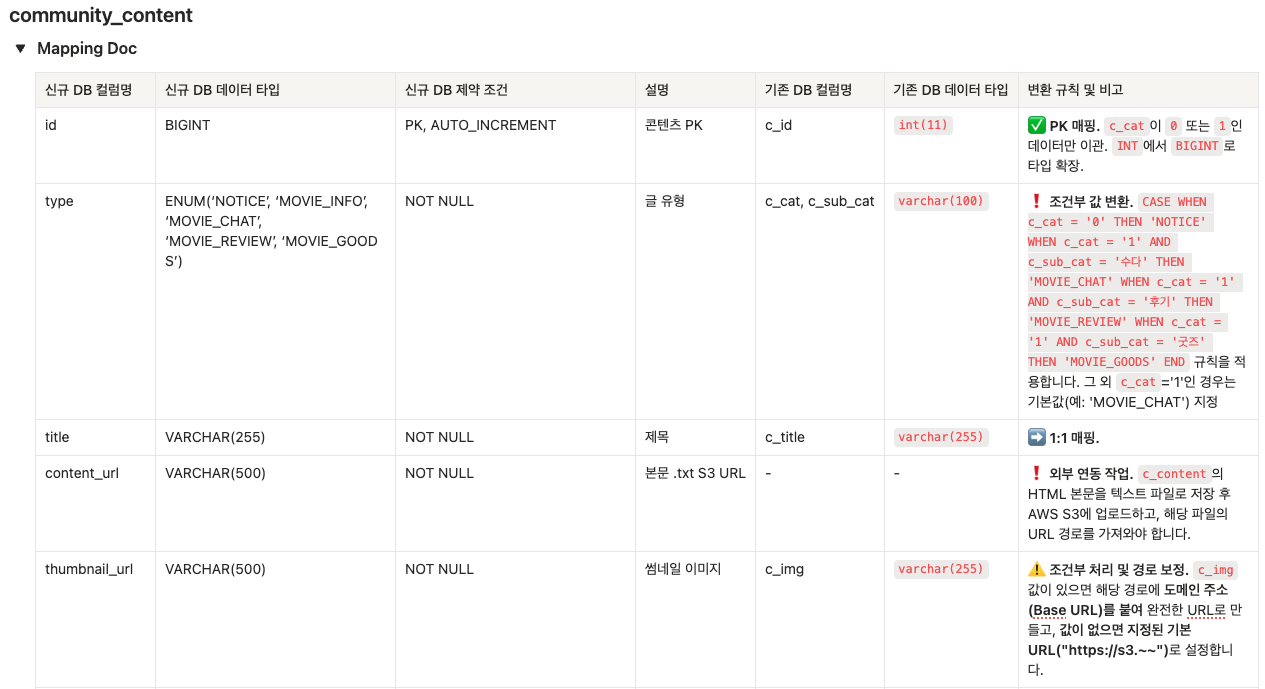
45개의 구형 테이블을 분석하여 신규 서비스에 필요한 데이터만 선별했습니다. 특히 앞서 수립한 전략에 따라 테이블 간의 의존성을 분석하여 이관 순서(Sequence)를 정의하는 데 많은 공을 들였습니다.
Step 2. Transform & Cleansing
스크립트 내에 비즈니스 로직을 태워 데이터를 가공했습니다.
- 암호 해독 : 코드 분석을 통해 파악한 상태 값(
0 -> PENDING,1 -> APPROVED)을 가독성 높은 ENUM 타입으로 변환하였습니다. - HTML to Text : 기존 HTML 본문을 파싱하여 태그를 제거하고 순수 텍스트 파일로 변환하여 DB에는 HTML 태그 상관 없이 데이터만 적재할 수 있도록 하였습니다.
Step 3. Load (DB + File)
이 과정에서 가장 신경 쓴 부분은 동기화입니다. DB 저장과 파일 업로드가 따로 놀지 않도록 트랜잭션 관리에 집중했습니다.
1 | try: |
데이터 정합성 검증 : 4단계 방어막
“이관 작업 완료했습니다”라는 말보다 중요한 건 데이터가 100% 정확하게 옮겨졌는가입니다. 저는 단순한 데이터 이동을 넘어, 신뢰할 수 있는 데이터베이스를 만들기 위해 4단계의 검증 파이프라인을 구축했습니다.
1단계: 수량 검증
가장 기초적이지만 필수적인 검증입니다. 단순히 전체 개수만 세는 것이 아니라, 논리적인 공식이 성립하는지를 확인했습니다.
1 | 검증 공식: [원본 데이터 총계] - [제외된 데이터(탈퇴/불량)] = [신규 DB 적재 건수] |
이 공식에서 단 1건의 오차라도 발생하면 파이프라인을 즉시 중단하고 원인을 분석하도록 설계하여, ‘원인 모를 유실’을 차단했습니다.
2단계: 참조 무결성 검증 (Referential Integrity)
관계형 데이터베이스(RDB)의 핵심인 테이블 간의 관계를 검증합니다. 고아 데이터가 발생하는 것을 막기 위해 ID 매핑 방식을 활용했습니다.
User Mapping: 구 mem_id와 신규 user_id의 매핑 테이블을 메모리에 로드해두고, 게시글 이관 시 작성자 정보가 매핑 테이블에 없다면(탈퇴했거나 제외된 계정) 해당 게시글도 과감히 제외했습니다.
Hierarchical Check: 대댓글(Child)을 옮길 때, 부모 댓글(Parent)이 이관 대상에 포함되어 있는지 먼저 확인합니다. 부모 없는 자식이 생기는 것을 방지하여 데이터의 일관성을 확보했습니다.
3단계: 데이터 품질 검증
단순 이동이 아니라, 신규 시스템의 엄격한 제약 조건(Constraint)을 통과할 수 있는 데이터만 선별했습니다. 이를 통해 Legacy 데이터가 신규 시스템을 오염시키는 것을 방지했습니다.
Format Validation: 이메일 정규식 검사를 통과하지 못하는 데이터 필터링
Logic Validation:
test,null,undefined등 개발 과정에서 생성된 더미 OAuth ID 필터링Duplication Check: 중복 계정 발견 시,
last_login_at이 가장 최근인 계정만 유지
4단계: 결과 리포팅
검증의 끝은 근거 남기기입니다. 스크립트 실행 후에는 반드시 결과 로그를 남겼습니다
Audit Log:
migration_report.txt를 통해 성공/실패 건수와 수행 시간을 기록했습니다.Error Tracking: 제외된 데이터는
excluded_users.csv와 같이 별도 파일로 저장하고, 제외 사유(예: Reason: Author Not Found)를 명시했습니다. 이를 통해 이관 후 문의가 들어오더라도 데이터를 역추적하여 명확한 답변을 줄 수 있는 근거를 마련했습니다.
트러블 슈팅 및 회고
이번 마이그레이션은 단순한 데이터 이동을 넘어, 기술 부채를 청산하고 시스템의 안정성을 확보하는 과정이었습니다. 그 과정에서 마주한 어려움을 통해 얻게 된 교훈을 공유합니다.
1. 매직 넘버(Magic Number) 제거와 데이터 명시성 확보
가장 큰 어려움은 문서화되지 않은 레거시 데이터 내의 불확실성이었습니다.
c_cat = 0과 같은 의미 불명의 숫자(Magic Number)들이 산재해 있었고, 이를 해석하기 위해 프론트엔드 렌더링 로직부터 백엔드 쿼리까지 역추적하는 리버스 엔지니어링이 필요했습니다
이 경험을 통해 코드는 그 자체로 문서의 역할을 해야 한다는 원칙을 재확인했습니다. 이에 따라 신규 시스템에서는 모호한 숫자 대신 직관적인 ENUM(NOTICE, MOVIE_CHAT) 타입을 도입하여, 후속 개발자가 별도의 문서 없이도 코드를 이해할 수 있도록 유지보수성을 강화했습니다.
2. I/O 병목 해결을 통한 성능 최적화 (80% 단축)
운영 환경 이관 시, 수천 장의 이미지를 순차적(Synchronous)으로 S3에 업로드하는 과정에서 Network I/O Latency가 전체 작업 시간의 90%를 점유하는 병목이 발생했습니다. 제한된 점검 시간(Downtime) 내에 작업을 완료하기 어려운 상황이었습니다.
이를 해결하기 위해 두 가지 최적화를 적용했습니다.
Concurrency:
Python ThreadPoolExecutor를 도입하여 이미지 업로드를 병렬 처리, 네트워크 대역폭 활용 극대화.Batch Processing: DB 적재 시 단건 처리가 아닌 Bulk Insert를 적용하여 트랜잭션 오버헤드 최소화.
결과적으로 전체 이관 시간을 초기 예상 대비 약 80% 단축시켰으며, 대용량 데이터 처리 시 시스템 리소스와 I/O 특성을 고려한 아키텍처 설계의 중요성을 체감했습니다.
마치며
이번 마이그레이션은 그동안 누적된 기술 부채를 청산하고, 서비스가 다시 빠르게 성장할 수 있는 기술적 토대를 마련하는 과정이었습니다.
이 기록이 복잡한 데이터 이관 문제로 고민 중인 분들께 작은 힌트가 되길 바랍니다.
긴 글 읽어주셔서 감사합니다.